

In a latest research printed within the journal JAMA Community Open, researchers evaluated two ChatGPT massive language fashions (LLMs) educated to reply questions from the American Board of Psychiatry and Neurology query financial institution. They in contrast these outcomes for each lower- and higher-order questions towards human neurology college students. They discovered that one of many two fashions considerably outperformed imply human scores on the query paper (85% versus 73.8%), thereby passing a usually difficult-to-clear entrance examination. These findings spotlight the latest developments in LLMs and present how, with minor tweaks, they might change into key sources for medical neurology functions.
Research: Efficiency of Massive Language Fashions on a Neurology Board–Fashion Examination. Picture Credit score: PopTika / Shutterstock
They’re getting smarter!
Machine studying (ML) and different synthetic intelligence (AI) algorithms are more and more being adopted throughout beforehand human-restricted fields, together with drugs, navy, schooling, and scientific analysis. With latest developments in computing energy and the event of ‘smarter’ AI fashions, these deep studying algorithms are actually extensively utilized in medical neurology for duties starting from neurological analysis to remedy and prognosis.
Not too long ago, transformer-based AI architectures – AI algorithms educated on intensive knowledge units of 45 terabytes or extra – are aiding and typically even changing people in historically solely human roles, together with neurology. The huge quantity of coaching knowledge, in tandem with repeatedly improved code, permits these fashions to current responses, recommendations, and predictions which can be each logical and correct. Two essential algorithms primarily based on the favored ChatGPT platform have hitherto been developed – LLM 1 (ChatGPT model 3.5) and LLM 2 (ChatGPT 4). The previous is computationally much less demanding and way more speedy in its knowledge processing, whereas the latter is contextually extra correct.
Although casual proof is in favor of the usefulness of those fashions, their efficiency and accuracy have not often been examined in a scientific setting. The restricted current proof comes from analysis into the efficiency of LLM 1 in the US Medical Licensing Examination (USMLE) and in ophthalmology examinations, with LLM 2 model being hitherto unvalidated.
In regards to the research
Within the current research, researchers aimed to check the efficiency of LLM 1 and a couple of towards human neurology college students in board-like written examinations. This cross-sectional research complies with the Strengthening the Reporting of Observational Research in Epidemiology (STROBE) tips and makes use of a neurology board examination as a proxy for LLM 1 and a couple of’s efficiency in extremely technical human medical examinations.
The research used questions from the publicly obtainable American Board of Psychiatry and Neurology (ABPN) query financial institution. The financial institution accommodates 2,036 questions, of which 80 had been excluded as a consequence of their being primarily based on offered movies or pictures. LLM 1 and LLM 2 had been obtained from server-contained on-line sources (ChatGPT 3.5 and 4, respectively) and had been educated till September 2021. Human comparisons had been made utilizing precise knowledge from earlier iterations of the ABPN board entrance examination.
Notably, throughout evaluations, pre-trained fashions LLM 1 and a couple of didn’t have entry to on-line sources to confirm or enhance their solutions. No neurology-specific mannequin tweaking or fine-tuning was carried out previous to mannequin testing. The testing course of comprised subjecting the fashions to 1,956 multiple-choice questions, every with one appropriate reply and between three and 5 distractors. All questions had been labeled as lower-order (fundamental understanding and reminiscence) and higher-order (utility, evaluation, or evaluative-thinking-based) questions following the Bloom taxonomy for studying and evaluation.
Analysis standards thought-about a rating of 70% or increased because the minimal passing grade for the examination. Fashions had been examined for reply reproducibility through 50 impartial queries designed to probe ideas of self-consistency.
“For the high-dimensional evaluation of query representations, the embeddings of those questions had been analyzed. These numeric vector representations embody the semantic and contextual essence of the tokens (on this context, the questions) processed by the mannequin. The supply of those embeddings is the mannequin parameters or weights, that are used to code and decode the texts for enter and output.”
Statistical evaluation consisted of a single-variable, order-specific comparability between fashions’ efficiency and former human outcomes utilizing a chi-squared (χ2) check (with Bonferroni corrections for 26 recognized query subgroups).
Research findings
LLM 2 confirmed the very best efficiency of all examined cohorts, acquiring a rating of 85.0% (1662 out of 1956 questions answered accurately). Compared, LLM 1 scored 66.8%, and people averaged 73.8%. Mannequin efficiency was discovered to be highest in lower-order questions (71.6% and 88.5%, respectively, for fashions 1 and a couple of).
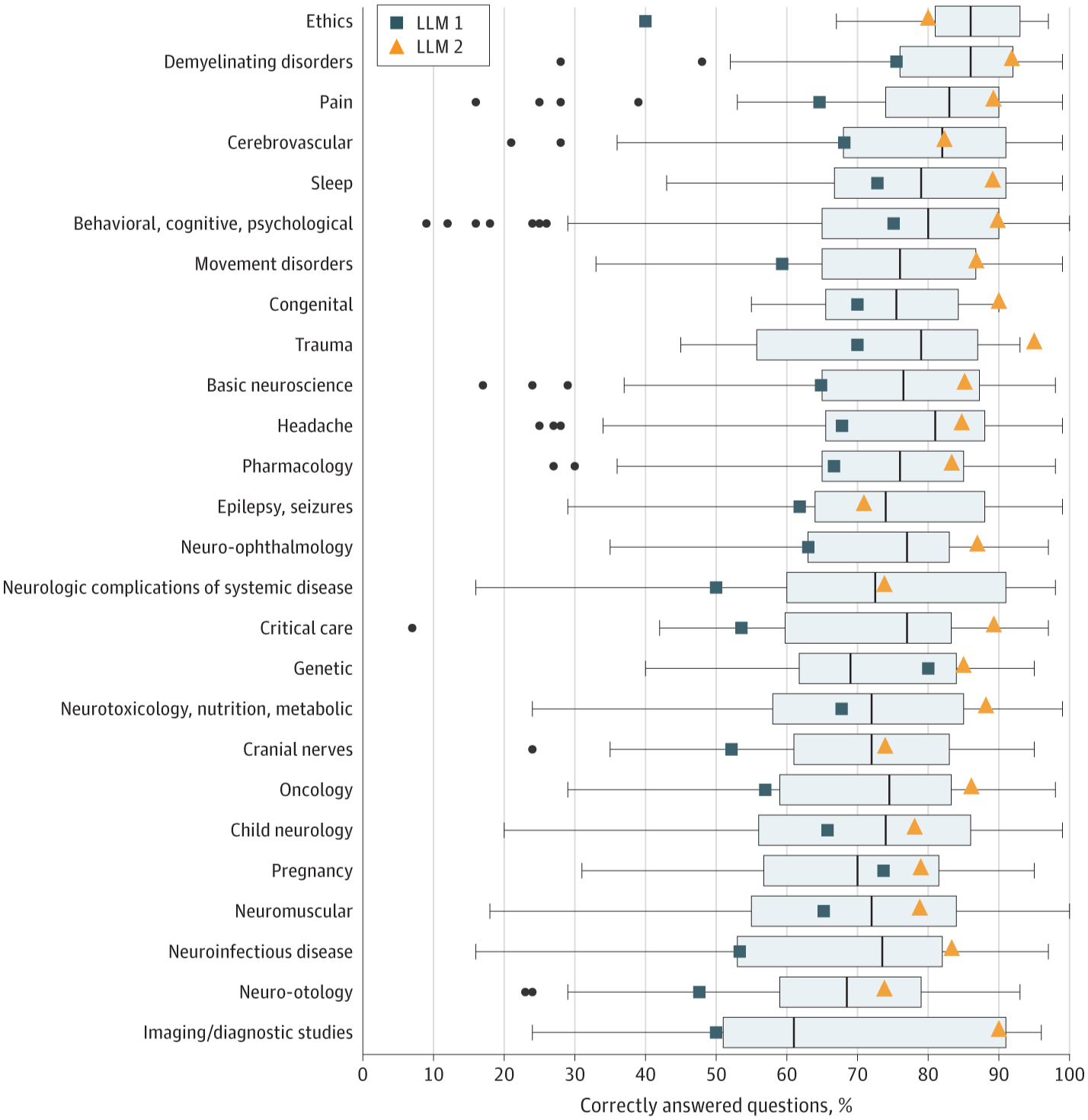 Boxplots illustrate human person rating distribution, with the black line indicating the median, the perimeters of the packing containers indicating first and third quartiles, and the whiskers indicating the biggest and smallest worth no additional than 1.5 × IQR from the decrease and higher edges. Dots point out outliers. LLM signifies massive language mannequin.
Boxplots illustrate human person rating distribution, with the black line indicating the median, the perimeters of the packing containers indicating first and third quartiles, and the whiskers indicating the biggest and smallest worth no additional than 1.5 × IQR from the decrease and higher edges. Dots point out outliers. LLM signifies massive language mannequin.
Apparently, LLM 1’s lower-order accuracy was much like that of human college students (71.6% versus 73.6%) however considerably decrease for higher-order questions (62.7% versus 73.9%). Simply half a era later, nonetheless, algorithm enhancements allowed ChatGPT model 4 to outcompete human college students in each lower- and higher-order accuracy.
“Within the behavioral, cognitive, psychological class, LLM 2 outperformed each LLM 1 and common check financial institution customers (LLM 2: 433 of 482 [89.8%]; LLM 2: 362 of 482 [75.1%]; human customers: 76.0%; P < .001). LLM 2 additionally exhibited superior efficiency in subjects corresponding to fundamental neuroscience, motion problems, neurotoxicology, vitamin, metabolic, oncology, and ache in contrast with LLM 1, whereas its efficiency aligned with the human person common"
Conclusions
Within the current research, researchers evaluated the efficiency of two ChatGPT LLMs in neurological board examinations. They discovered that the later mannequin considerably outperformed each the sooner mannequin, and human neurology college students throughout lower- and higher-order questions. Regardless of displaying higher strengths in memory-based questions in comparison with these requiring cognition, these outcomes spotlight these fashions’ potential in aiding and even changing human medical consultants in non-mission-critical roles.
Notably, these fashions weren’t tweaked for neurological functions, nor had been they allowed entry to consistently updating on-line sources, each of which may additional enhance the efficiency positive factors between them and their human creators. In a nutshell, AI LLMs are getting smarter at an unprecedented tempo.
On a jovial observe, the creator of this text (who has no affiliation with the research authors) recommends that the time-traveling cyborgs are ready for speedy deployment as a safeguard if and when the LLMs notice how sensible they’re!